# Redis面试 - redis问题总结
# 常规问题
什么是redis,为什么要使用它
Redis的的是完全开源免费的,遵守BSD协议,是一个高性能的键值数据库。是当前最热门的的的NoSql数据库之一,也被人们称为数据结构服务器。Redis以内存作为数据存储介质,所以读写数据的效率极高,远远超过数据库。以设置和获取一个256字节字符串为例,它的读取速度可高达110000次/s,写速度高达81000次/s。
Redis跟memcache不同的是,储存在Redis中的数据是持久化的,断电或重启后,数据也不会丢失。因为Redis的存储分为内存存储、磁盘存储和log文件三部分,重启后,Redis可以从磁盘重新将数据加载到内存中,这些可以通过配置文件对其进行配置,正因为这样,Redis才能实现持久化。
Redis支持主从模式,可以配置集群,这样更利于支撑起大型的项目,这也是Redis的一大亮点。 众多语言都支持Redis,因为Redis交换数据快,所以在服务器中常用来存储一些需要频繁调取的数据,这样可以大大节省系统直接读取磁盘来获得数据的I/O开销,更重要的是可以极大提升速度。
redis一般有哪些使用场景
- 缓存
- 数据共享分布式
- 分布式锁
- 全局ID
- 计数器
- 限流
- 位统计
- 购物车
- 用户消息时间线timeline
- 消息队列 (opens new window)
- 抽奖
- 点赞、签到、打卡
- 商品标签
- 商品筛选
- 用户关注、推荐模型
- 排行榜
redis为什么快
Redis是基于内存存储实现的数据库,相对于数据存在磁盘的数据库,就省去磁盘磁盘I/O的消耗。 MySQL等磁盘数据库,需要建立索引来加快查询效率,而Redis数据存放在内存,直接操作内存,所以就很快。
# # 数据类型和数据结构
redis有哪些数据类型
string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
redis数据类型有哪些命令
谈谈redis的对象机制(redisObject)
https://developer.aliyun.com/article/937283
Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
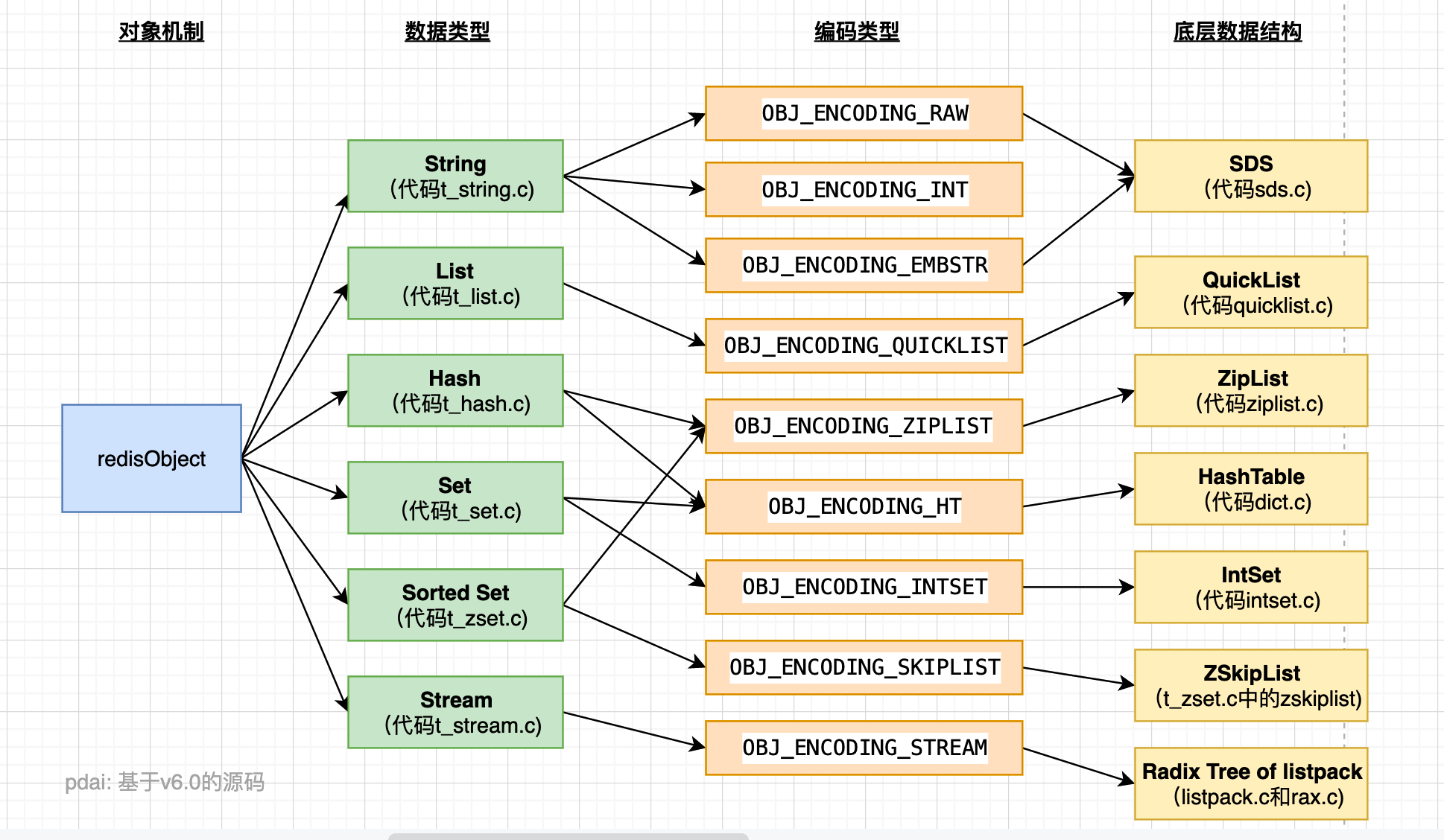
Redis的每种对象其实都由对象结构(redisObject) 与 对应编码的数据结构组合而成,而每种对象类型对应若干编码方式,不同的编码方式所对应的底层数据结构是不同的。
所以,我们需要从几个个角度来着手底层研究:
- 对象设计机制: 对象结构(redisObject)
- 编码类型和底层数据结构: 对应编码的数据结构
# 为什么Redis会设计redisObject对象
为什么Redis会设计redisObject对象?
在redis的命令中,用于对键进行处理的命令占了很大一部分,而对于键所保存的值的类型(键的类型),键能执行的命令又各不相同。如: LPUSH 和 LLEN 只能用于列表键, 而 SADD 和SRANDMEMBER 只能用于集合键, 等等; 另外一些命令, 比如 DEL、 TTL 和 TYPE, 可以用于任何类型的键;但是要正确实现这些命令, 必须为不同类型的键设置不同的处理方式: 比如说, 删除一个列表键和删除一个字符串键的操作过程就不太一样。
以上的描述说明, Redis 必须让每个键都带有类型信息, 使得程序可以检查键的类型, 并为它选择合适的处理方式.
比如说, 集合类型就可以由字典和整数集合两种不同的数据结构实现, 但是, 当用户执行 ZADD 命令时, 他/她应该不必关心集合使用的是什么编码, 只要 Redis 能按照 ZADD 命令的指示, 将新元素添加到集合就可以了。
这说明, 操作数据类型的命令除了要对键的类型进行检查之外, 还需要根据数据类型的不同编码进行多态处理.
为了解决以上问题, Redis 构建了自己的类型系统, 这个系统的主要功能包括:
- redisObject 对象.
- 基于 redisObject 对象的类型检查.
- 基于 redisObject 对象的显式多态函数.
- 对 redisObject 进行分配、共享和销毁的机制.
# 命令的类型检查和多态
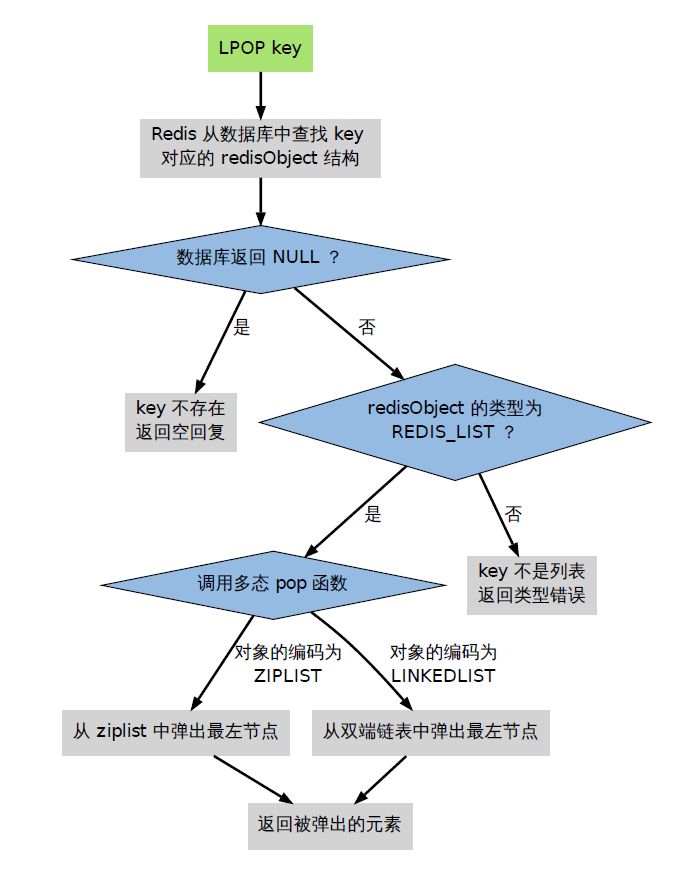
那么Redis是如何处理一条命令的呢?
当执行一个处理数据类型命令的时候,redis执行以下步骤
- 根据给定的key,在数据库字典中查找和它相对应的redisObject,如果没找到,就返回NULL;
- 检查redisObject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误;
- 根据redisObject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构;
- 返回数据结构的操作结果作为命令的返回值。
比如现在执行LPOP命令:
# 对象共享
redis一般会把一些常见的值放到一个共享对象中,这样可使程序避免了重复分配的麻烦,也节约了一些CPU时间。
redis预分配的值对象如下:
- 各种命令的返回值,比如成功时返回的OK,错误时返回的ERROR,命令入队失误时返回的QUEUE,等等
- 包括0 在内,小于REDIS_SHARED_INTEGERS的所有整数(REDIS_SHARED_INTEGERS的默认值是10000)

注意:共享对象只能被字典和双向链表这类能带有指针的数据结构使用。像整数集合和压缩列表这些只能保存字符串、整数等自勉之的内存数据结构
为什么redis不共享列表对象、哈希对象、集合对象、有序集合对象,只共享字符串对象?
- 列表对象、哈希对象、集合对象、有序集合对象,本身可以包含字符串对象,复杂度较高。
- 如果共享对象是保存字符串对象,那么验证操作的复杂度为O(1)
- 如果共享对象是保存字符串值的字符串对象,那么验证操作的复杂度为O(N)
- 如果共享对象是包含多个值的对象,其中值本身又是字符串对象,即其它对象中嵌套了字符串对象,比如列表对象、哈希对象,那么验证操作的复杂度将会是O(N的平方)
如果对复杂度较高的对象创建共享对象,需要消耗很大的CPU,用这种消耗去换取内存空间,是不合适的
# 引用计数以及对象的消毁
redisObject中有refcount属性,是对象的引用计数,显然计数0那么就是可以回收。
- 每个redisObject结构都带有一个refcount属性,指示这个对象被引用了多少次;
- 当新创建一个对象时,它的refcount属性被设置为1;
- 当对一个对象进行共享时,redis将这个对象的refcount加一;
- 当使用完一个对象后,或者消除对一个对象的引用之后,程序将对象的refcount减一;
- 当对象的refcount降至0 时,这个RedisObject结构,以及它引用的数据结构的内存都会被释放。
# 小结
redis使用自己实现的对象机制(redisObject)来实现类型判断、命令多态和基于引用次数的垃圾回收;
redis会预分配一些常用的数据对象,并通过共享这些对象来减少内存占用,和避免频繁的为小对象分配内存。
redis数据类型有哪些底层数据结构
简单动态字符串(SDS)链表 字典 跳跃表 整数集合 压缩列表
为什么要设计sds?
一个字符串类型的值能存储最大容量是多少?512M
为什么会设计Stream
Redis5.0 中还增加了一个数据结构Stream,从字面上看是流类型,但其实从功能上看,应该是Redis对消息队列(MQ,Message Queue)的完善实现。
用过Redis做消息队列的都了解,基于Reids的消息队列实现有很多种,例如:
PUB/SUB,订阅/发布模式
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
基于
List LPUSH+BRPOP
或者
基于Sorted-Set
的实现
- 支持了持久化,但是不支持多播,分组消费等
为什么上面的结构无法满足广泛的MQ场景? 这里便引出一个核心的问题:如果我们期望设计一种数据结构来实现消息队列,最重要的就是要理解设计一个消息队列需要考虑什么?初步的我们很容易想到
- 消息的生产
- 消息的消费
- 单播和多播(多对多)
- 阻塞和非阻塞读取
- 消息有序性
- 消息的持久化
Stream用在什么样场景
消息ID的设计是否考虑了时间回拨的问题
# # 持久化和内存
- Redis 的持久化机制是什么?各自的优缺点?一般怎么用?
- Redis 过期键的删除策略有哪些
- Redis 内存淘汰算法有哪些
- Redis的内存用完了会发生什么? 如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
- Redis如何做内存优化?
- Redis key 的过期时间和永久有效分别怎么设置?
EXPIRE 和 PERSIST 命令
- Redis 中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应,这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多 POP3 协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
# # 事务
- 什么是redis事务
- Redis事务相关命令
- Redis事务的三个阶段
- watch是如何监视实现的呢
- 为什么 Redis 不支持回滚
- redis 对 ACID的支持性理解
- Redis事务其他实现
基于Lua脚本,Redis可以保证脚本内的命令一次性、按顺序地执行,其同时也不提供事务运行错误的回滚,执行过程中如果部分命令运行错误,剩下的命令还是会继续运行完
基于中间标记变量,通过另外的标记变量来标识事务是否执行完成,读取数据时先读取该标记变量判断是否事务执行完成。但这样会需要额外写代码实现,比较繁琐
# # 集群
# # 主从复制
- Redis集群的主从复制模型是怎样的?
- 全量复制的三个阶段?
- 为什么会设计增量复制?
- 增量复制的流程? 如果在网络断开期间,repl_backlog_size环形缓冲区写满之后,从库是会丢失掉那部分被覆盖掉的数据,还是直接进行全量复制呢?
- 为什么不持久化的主服务器自动重启非常危险呢?
- 为什么主从全量复制使用RDB而不使用AOF?
- 为什么还有无磁盘复制模式?
- 为什么还会有从库的从库的设计?
# # 哨兵机制
- Redis哨兵机制?哨兵实现了什么功能呢
- 哨兵集群是通过什么方式组建的?
- 哨兵是如何监控Redis集群的?
- 哨兵如何判断主库已经下线了呢?
- 哨兵的选举机制是什么样的?
- Redis 1主4从,5个哨兵,哨兵配置quorum为2,如果3个哨兵故障,当主库宕机时,哨兵能否判断主库“客观下线”?能否自动切换?
- 主库判定客观下线了,那么如何从剩余的从库中选择一个新的主库呢?
- 新的主库选择出来后,如何进行故障的转移?
# # Redis集群
- 说说Redis哈希槽的概念?为什么是16384个?
- Redis集群会有写操作丢失吗?为什么?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
# # 应用场景
- redis 客户端有哪些
Redisson、Jedis、lettuce等等,官方推荐使用Redisson。
Redisson是一个高级的分布式协调Redis客服端,能帮助用户在分布式环境中轻松实现一些Java的对象 (Bloom filter, BitSet, Set, SetMultimap, ScoredSortedSet, SortedSet, Map, ConcurrentMap, List, ListMultimap, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, ReadWriteLock, AtomicLong, CountDownLatch, Publish / Subscribe, HyperLogLog)。
- Redis如何做大量数据插入? Redis2.6开始redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
- redis实现分布式锁实现? 什么是 RedLock?
- redis缓存有哪些问题,如何解决
- redis和其它数据库一致性问题如何解决
- redis性能问题有哪些,如何分析定位解决
# # 新版本
- Redis单线程模型? 在6.0之前如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
著作权归@pdai所有 原文链接:https://pdai.tech/md/db/nosql-redis/db-redis-z-mianshi.html